Naive Bayes Classifier in JavaScript
The Naive Bayes classifier is a pretty popular text classification algorithm because of it’s simplicity. You’ll often see this classifier used for spam detection, authorship attribution, gender authentication, determing whether a review is positive or negative, and even sentiment analysis. The Naive Bayes classifier takes in a corpus (body of text) known as a document, which then a stemmer runs through the document and returns a “bag or words” so to speak. Stemming is the process of reducing an inflected word to it’s word stem (root). For example, the stem of the words “dreaming”, “dreamer”, and “dreamed”, is just “dream”.
In the code example below, I am using the Porter Stemming algorithm and the Bayes classifier algorithm implementations from the excellent general natural language facility library for node, natural by Chris Umbel.
The way Naive Bayes classifier works is it counts the frequencies of the stemmed words. These are called features. A class can contain many features. A document can contain many features of a class. Initial we must train the classifier to learn what class features belong to. Once the classifier has enough knowledge of classed features, we can asked it to classify a new document based on prior classifications. The algorithm is considered naive because it does not take account of where in the document the words are positioned. But it turns out that that algorithm does a pretty good job of classification even though it is not aware of context.
Algorithm
What is the probability of the class given the document?
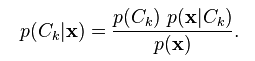
P(c|d) = P(c)P(d|c)
Probability of the class given the document is equal to the probability of the class times the probability of the document given the class
The denominator can be dropped because it is a constant. For example, if we have one document and 10 classes and only one class can classify document, the probability of the document is the same.
/**
* Terminology
*
* label: refers to class as in classification, since `class` is a reserved word.
* doc: refers to document, since `document` is a reserved word.
* feature: a token (word) in the bag of words (document).
*/
/**
* Include Porter Stemmer algorithm
* https://github.com/miguelmota/bayes-classifier/blob/master/lib/stemmers/porter.js
*/
var stemmer = require('./porter-stemmer');
/**
* BayesClassifier
* @desc Bayes classifier constructor
* @constructor
* @return Bayes classifier instance
*/
function BayesClassifier() {
/*
* Create a new instance when not using the `new` keyword.
*/
if (!(this instanceof BayesClassifier)) {
return new BayesClassifier();
}
/*
* The stemmer provides tokenization methods.
* It breaks the doc into words (tokens) and takes the
* stem of each word. A stem is a form to which affixes
* can be attached, aka root word.
*/
this.stemmer = stemmer;
/*
* A collection of added documents
* Each document is an object containing the class, and array of stemmed words.
*/
this.docs = [];
/*
* Index of last added document.
*/
this.lastAdded = 0;
/*
* A map of all class features.
*/
this.features = {};
/*
* A map containing each class and associated features.
* Each class has a map containing a feature index and the count of feature appearances for that class.
*/
this.classFeatures = {};
/*
* Keep track of how many features in each class.
*/
this.classTotals = {};
/*
* Number of examples trained
*/
this.totalExamples = 1;
/* Additive smoothing to eliminate zeros when summing features,
* in cases where no features are found in the document.
* Used as a fail-safe to always return a class.
* http://en.wikipedia.org/wiki/Additive_smoothing
*/
this.smoothing = 1;
}
/**
* AddDocument
* @param {array|string} doc - document
* @param {string} label - class
* @return {object} - Bayes classifier instance
*/
BayesClassifier.prototype.addDocument = function(doc, label) {
if (!this._size(doc)) {
return;
}
if (this._isString(doc)) {
// Return array of stemmed words
doc = this.stemmer.tokenizeAndStem(doc);
}
var docObj = {
label: label,
value: doc
};
this.docs.push(docObj);
// Add token (feature) to features map
for (var i = 0; i < doc.length; i++) {
this.features[doc[i]] = 1;
}
};
/**
* AddDocuments
* @param {array} docs - documents
* @param {string} label - class
* @return {object} - Bayes classifier instance
*/
BayesClassifier.prototype.addDocuments = function(docs, label) {
for (var i = 0; i < docs.length; i++) {
this.addDocument(docs[i], label);
}
};
/**
* docToFeatures
*
* @desc
* Returns an array with 1's or 0 for each feature in document
* A 1 if feature is in document
* A 0 if feature is not in document
*
* @param {string|array} doc - document
* @return {array} features
*/
BayesClassifier.prototype.docToFeatures = function(doc) {
var features = [];
if (this._isString(doc)) {
doc = this.stemmer.tokenizeAndStem(doc);
}
for (var feature in this.features) {
features.push(Number(!!~doc.indexOf(feature)));
}
return features;
};
/**
* classify
* @desc Returns class with highest probability for document.
* @param {string} doc - document
* @return {string} class
*/
BayesClassifier.prototype.classify = function(doc) {
var classifications = this.getClassifications(doc);
if (!this._size(classifications)) {
throw 'Not trained';
}
return classifications[0].label;
};
/**
* train
* @desc train the classifier on the added documents.
* @return {object} - Bayes classifier instance
*/
BayesClassifier.prototype.train = function() {
var totalDocs = this.docs.length;
for (var i = this.lastAdded; i < totalDocs; i++) {
var features = this.docToFeatures(this.docs[i].value);
this.addExample(features, this.docs[i].label);
this.lastAdded++;
}
};
/**
* addExample
* @desc Increment the counter of each feature for each class.
* @param {array} docFeatures
* @param {string} label - class
* @return {object} - Bayes classifier instance
*/
BayesClassifier.prototype.addExample = function(docFeatures, label) {
if (!this.classFeatures[label]) {
this.classFeatures[label] = {};
this.classTotals[label] = 1;
}
this.totalExamples++;
if (this._isArray(docFeatures)) {
var i = docFeatures.length;
this.classTotals[label]++;
while(i--) {
if (docFeatures[i]) {
if (this.classFeatures[label][i]) {
this.classFeatures[label][i]++;
} else {
this.classFeatures[label][i] = 1 + this.smoothing;
}
}
}
} else {
for (var key in docFeatures) {
value = docFeatures[key];
if (this.classFeatures[label][value]) {
this.classFeatures[label][value]++;
} else {
this.classFeatures[label][value] = 1 + this.smoothing;
}
}
}
};
/**
* probabilityOfClass
* @param {array|string} docFeatures - document features
* @param {string} label - class
* @return probability;
* @desc
* calculate the probability of class for the document.
*
* Algorithm source
* http://en.wikipedia.org/wiki/Naive_Bayes_classifier
*
* P(c|d) = P(c)P(d|c)
* ---------
* P(d)
*
* P = probability
* c = class
* d = document
*
* P(c|d) = Likelyhood(class given the document)
* P(d|c) = Likelyhood(document given the classes).
* same as P(x1,x2,...,xn|c) - document `d` represented as features `x1,x2,...xn`
* P(c) = Likelyhood(class)
* P(d) = Likelyhood(document)
*
* rewritten in plain english:
*
* posterior = prior x likelyhood
* ------------------
* evidence
*
* The denominator can be dropped because it is a constant. For example,
* if we have one document and 10 classes and only one class can classify
* document, the probability of the document is the same.
*
* The final equation looks like this:
* P(c|d) = P(c)P(d|c)
*/
BayesClassifier.prototype.probabilityOfClass = function(docFeatures, label) {
var count = 0;
var prob = 0;
if (this._isArray(docFeatures)) {
var i = docFeatures.length;
// Iterate though each feature in document.
while(i--) {
// Proceed if feature collection.
if (docFeatures[i]) {
/*
* The number of occurances of the document feature in class.
*/
count = this.classFeatures[label][i] || this.smoothing;
/* This is the `P(d|c)` part of the model.
* How often the class occurs. We simply count the relative
* feature frequencies in the corpus (document body).
*
* We divide the count by the total number of features for the class,
* and add it to the probability total.
* We're using Natural Logarithm here to prevent Arithmetic Underflow
* http://en.wikipedia.org/wiki/Arithmetic_underflow
*/
prob += Math.log(count / this.classTotals[label]);
}
}
} else {
for (var key in docFeatures) {
count = this.classFeatures[label][docFeatures[key]] || this.smoothing;
prob += Math.log(count / this.classTotals[label]);
}
}
/*
* This is the `P(c)` part of the model.
*
* Divide the the total number of features in class by total number of all features.
*/
var featureRatio = (this.classTotals[label] / this.totalExamples);
/**
* probability of class given document = P(d|c)P(c)
*/
prob = featureRatio * Math.exp(prob);
return prob;
};
/**
* getClassifications
* @desc Return array of document classes their probability values.
* @param {string} doc - document
* @return classification ordered by highest probability.
*/
BayesClassifier.prototype.getClassifications = function(doc) {
var classifier = this;
var labels = [];
for (var className in this.classFeatures) {
labels.push({
label: className,
value: classifier.probabilityOfClass(this.docToFeatures(doc), className)
});
}
return labels.sort(function(x, y) {
return y.value - x.value;
});
};
/*
* Helper utils
*/
BayesClassifier.prototype._isString = function(s) {
return typeof(s) === 'string' || s instanceof String;
};
BayesClassifier.prototype._isArray = function(s) {
return Array.isArray(s);
};
BayesClassifier.prototype._isObject = function(s) {
return typeof(s) === 'object' || s instanceof Object;
};
BayesClassifier.prototype._size = function(s) {
if (this._isArray(s) || this._isString(s) || this._isObject(s)) {
return s.length;
}
return 0;
};
/*
* Export constructor
*/
module.exports = BayesClassifier;
Usage
Now we get to use the Bayes classifier. Here’s an example to classify a statement as either positive or negative. The algorithm must first learn from a training set of data.
var BayesClassifier = require('../bayes-classifier');
var classifier = new BayesClassifier();
var positiveDocuments = [
'I love tacos.',
'Dude, that burrito was epic!',
'Holy cow, these nachos are so good and tasty.',
'I am drooling over the awesome bean and cheese quesadillas.'
];
var negativeDocuments = [
'Gross, worst taco ever.',
'The buritos gave me horrible diarrhea.',
'I\'m going to puke if I eat another bad nacho.',
'I\'d rather die than eat those nasty enchiladas.'
];
classifier.addDocuments(positiveDocuments, 'positive');
classifier.addDocuments(negativeDocuments, 'negative');
classifier.train();
console.log(classifier.classify('I heard the mexican restaurant is great!')); // "positive"
console.log(classifier.classify('I don\'t want to eat there again.')); // "negative"
console.log(classifier.classify('The torta is epicly bad.')); // "negative"
console.log(classifier.classify('The torta is horribly awesome.')); // "positive"
Conclusion
Hopefully the code was easy to follow. The full code is available on github as a node module. Definitely checkout the natural library for more text classification algorithms. The library contains many general natural language facilities, such as tokenization, stemming, classification, phonetics, tf-idf, WordNet, and string similarity.