Evolution of Blockchain Components to Off-Chain Models
The major components of blockchain are:
- Consensus
- Networking
- Record keeping
- Computation
A blockchain is a shared state database that records outputs from transactions. The inputs for these computations are new inputs and current state from previously computed results. State transition updates are broadcasted via peer-to-peer networking and each node validates the incoming state updates to reach consensus.
Blockchain brings the ability to execute programs in a trustless fashion by having every participating node in the network perform the computation and reach consensus on resulting output, where the output is then recorded into an immutable ledger.
The downside to this approach is that it’s highly infeasible to reach web-scale performance because of the throughput limitations. Currently computations must be computed within the allocated block time. For example, EOS has a block time of 500ms so therefore each transaction is limited to 150ms transaction times in order to fit within the allocated block time.
Public ledgers like Ethereum, require all nodes in the network to hold all the data of the chain in order to be able to validate transactions. The downside to this is that privacy is harder to achieve because all inputs to methods and outputs of transactions are publicly visible.
We’ll be exploring how components such as record keeping (storage) and smart contracts (computation) can be moved off-chain to enable more robust computations and storage requirements without sacrificing security and scalability requirements.
Off-Chain
Moving certain components alleviate some of the concerns mentioned. For example, with off-chain storage the data no longer needs to be hosted by all nodes but only by the nodes that are performing the computation. Another example, is that the computation engine doesn’t need to be pegged to the layer 1 chain; the computation can be performed as an off-chain task, analogous to a serverless platform such as Function as a Service (FaaS), using a different execution environment decoupled from the blockchain node. Because execution is no longer coupled with the chain software, the computation can be performed on a different node or server. This means that the layer 1 chain is now used as a means to register inputs and outputs and as a means to kick off computations to compute providers.
Off-chain data storage reduces the storage requirements that each node is expected to store. Storing data outside the layer 1 chain means that participants interested in processing transactions for a particular application are the ones who need to store the data and not every other node, although they can if they wish so.
A peril of off-chain data storage is data availability is no longer guaranteed since the data is not part of the blockchain but only a fingerprint of the data is stored on-chain. If the data is missing then computation cannot be performed so this affects the liveness of this application which is not good. However another trade off is that data stored off chain can remain private and confidential since not all nodes need to know what the data is but only those computing the tasks.
Off-chain computation reduces to high extent redundant computations required to achieve consensus. A layer 1 chain can hold only the most minimum and necessary information to be able to perform validations, while computations are computed off-chain but record the deterministic output of the state transition function. Off-chain computation can be coupled with off-chain storage as the means for reading inputs, pulling applications, and recording outputs.
If you think about what blockchains like Ethereum do, they aggregate transactions, order them by the order received via the sequential nonce per account, and then order them based on which transactions offer the highest fees. In proof-of-work systems, each node in the network performs the same routine which results in each node having the same limitations and not to mentioned wasted computational efforts.
In a typical layer 1 chain like Ethereum, the state transition system looks like this:
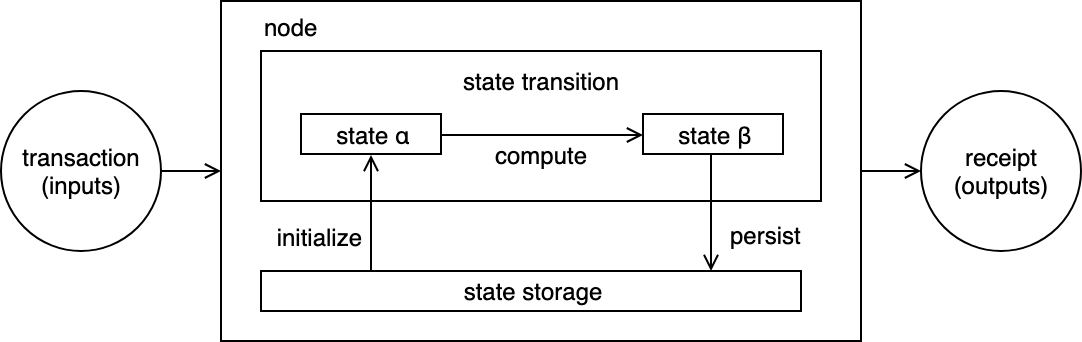
On-chain storage and computation
The node receives the transactions which includes data such as which smart contract and method to invoke as well as the inputs for that method. The node reads current state and executes the transaction creating a new state and persist that state all in the same node. This means all nodes that are redundantly computing the transaction also redundantly persist all the same information in their own node. the storage can be offloaded to separate storage nodes off-chain as we’ll see next.
Off-chain Storage
When we start abstracting away storage to an off-chain provider, we immediately reduce redundant storage requirements. In this scenario, when a transaction is received by the chain node must fetch the initial state from the storage node. After the computation, the chain node send the resulting state to the storage node to persist.
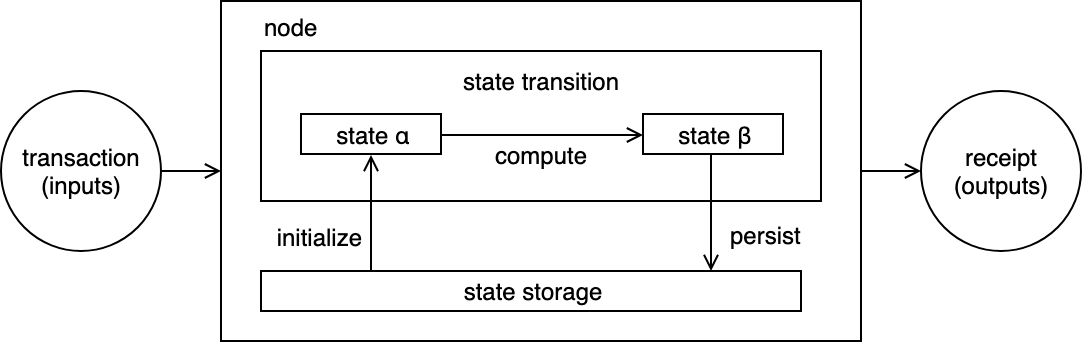
Off-chain storage with on-chain computation
There is one additional step which is the computing node must verify the data received form the storage node. This chain node only stores fingerprints of the data to check for integrity. For example, if using IPFS for off-chain storage, the chain node stores the content hash of the data. When the data is received from the storage node, the blockchain node recomputes the content hash to verify its the expected data. Similarly, after computing the output state, the data is stored off-chain on IPFS and its content hash is store on-chain for reference.
An important thing to be aware of, is that when placing storage off-chain we lose the durability principle in the ACID (Atomicity, Consistency, Isolation, Durability) model. Having data live on-chain guarantees that the data will be available but moving it off-chain only guarantees that we’ll be able to verify the integrity of the data (consistency) if we actually have the data.
Some projects using off-chain storage are Enigma; where only a reference is stored on-chain, Holochain; uses an agent-centric architecture where each dapp maintains their own distributed hash table, Blockstack; where peer nodes only maintain a zone file specifying where to download the data off-chain, Lisk; where all applications run as sidechains storing their own data and no app data on-chain, Dispatch Labs; where fingerprints are stored on-chain, with ability to upload and download data though data farmers, MultiChain; where information can be published to off-chain streams and nodes can subscribe to these streams, Polkadot: where each parallel chain (parachain) is responsible for storing their own data and the relay chain mainly persists accounting information and block headers.
Ethereum is considering a renting approach for state storage where nodes can be payed to store data otherwise they only store the fingerprint.
Off-Chain Computation
Similarity how storage can be offloaded off-chain, computation can be offloaded in similar fashion. The state transition function can be computed by a separated node to that of the chain node. Here we show how a chain node offloads the computation to a compute and the compute node reads the data from chain node:
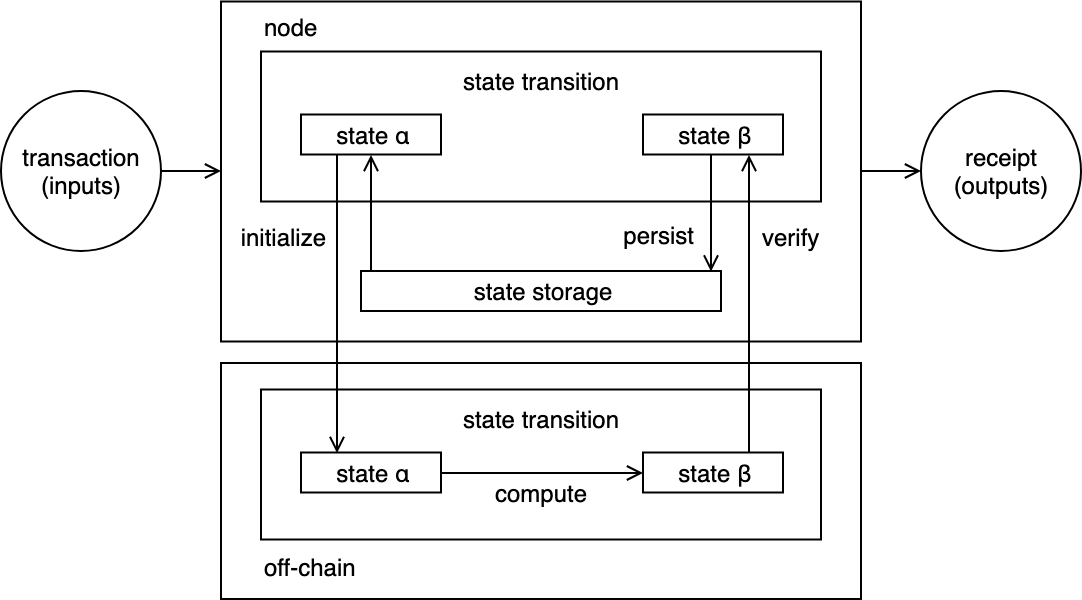
On-chain storage and off-chain computation
In this scenario all data is stored on-chain and the chain node sends the computation request to the off-chain computing node along with the data needed. The off-chain node run the state transition function to compute the output state.
Since the computation is offloaded off-chain, the chain node nows needs to perform verification of the resulting state because the computing node may report a false output state. The verification mechanism can simply be verifying that the resulting output was signed by the computing node which is whom the chain node is expecting the results from.
The new state is persisted after verification is achieved.
Serverless
Because the computation is decoupled from the blockchain node, this means the computation can be ran as a serverless function such as on Lamba, OpenFaaS, or Kubeless. Off-chain computation allows the combination of blockchain ledger maintained state with serverless functions. You can imagine an ecosystem of chain nodes, task orchestrators, and workers:
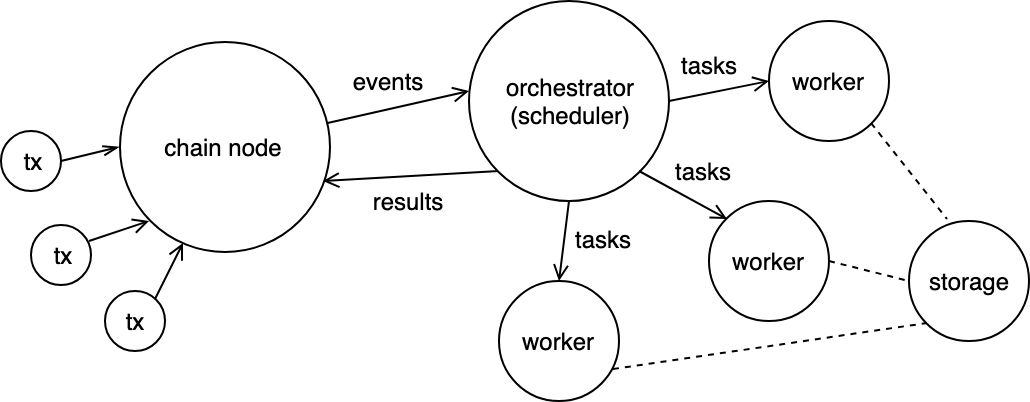
Off-chain clusters of workers
For example, the blockchain can be utilized as an event based system to register transactions that initiate off-chain work. You can have a Kubernetes cluster where the master node watches for on-chain requests and distributes workloads to its respective worker nodes in the form of a task which can be a serverless function or a lightweight Docker image. The execution is sandboxed by the Kubernetes runtime environment cri-o and there’s always the option to enable higher security by using for example, unikernels, which couples the essential parts of the kernel with the application in order to isolate the application from the host. Another option is to use use micro-VMs such as KataContainers, or Firecracker which is being used by AWS Lambda and AWS Fargate.
To ensure correctness of the computations, the orchestrating node might redundantly issue the same task to multiple workers and go with the result of the majority. In an open market, anyone with spare compute power can join a cluster of workers and be rewarded by the master controller upon completing tasks.
Besides task-based off-chain computation, another form is simply being able to rent server space for an allocated period of time. Because it’s difficult to determine whether a resource provider is actually providing the resources they say they are, this approach tends to rely on the Web of Trust to expand a network of reputation and credibility.
Some projects in the off-chain compute space are Truebit, Golem, SONM, Arbitrum, iExec, Akash, Hypernet, ArcBlock, and Transmute.
Off-Chain Storage and Computation (hybrid model)
Combining both off-chain storage and off-chain computation enables the best of both worlds. Here’s an overview of how the two models can be interwound: Off-chain storage and off-chain computation. With this hybrid model, better scalability is achieved:
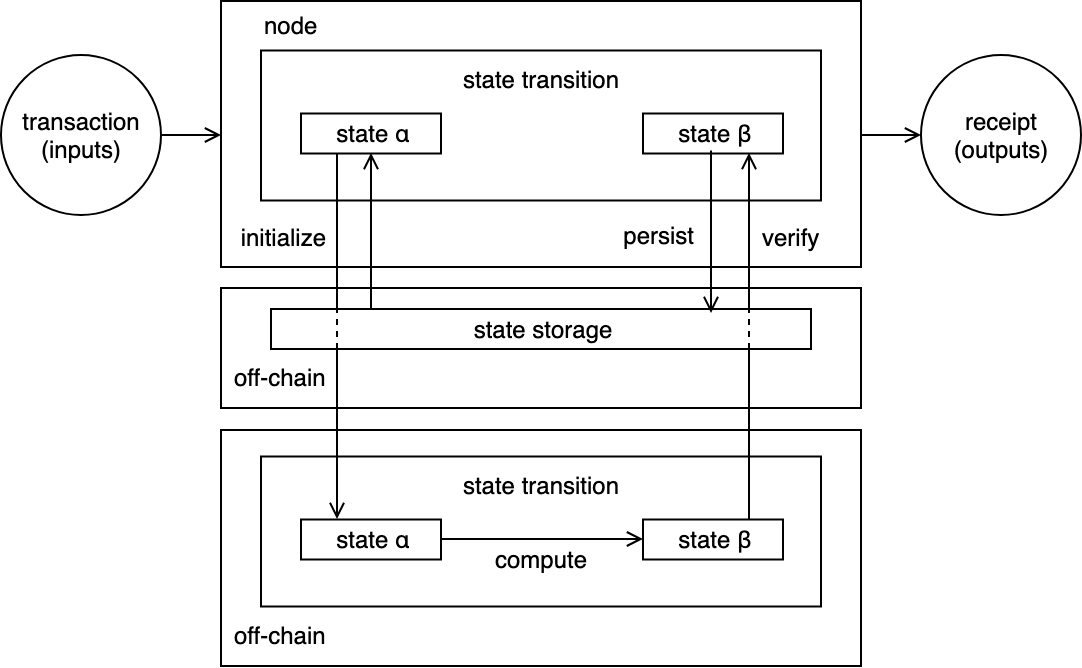
Off-chain storage and off-chain computation
An example is Plasma, it combines both off-chain storage and computation. Plasma is a hierarchy of blockchains where each child blockchain computes state transitions but is pegged to its parent chain; child chain periodically write back to the parent chain. each child chain is responsible for persistent their own data off-chain. This allows child chains to run at their own pace. Parent chains can check state transitions which means state transitions f subsidiary child chains are guaranteed to be correct.
Verifying Off-Chain Computations
The node that computes a computation off-chain is known as the Prover. The Prover submits the results with an attestation of the computations correctness.
A node that verifies the proof is known as the Verifier. The verifier check is the proof is valid and can persist result if successful.
To reduce load on the network, the verification should be non-interactive meaning that the verifier should be able to check the proof in one message to avoid back and forth with the prover. The verification should also be cheap meaning it’s size should be small and that it can be computed relatively quickly and on-chain.
Zk-SNARKs cryptography allows for both of these requirements. The message can be verified in one step and on-chain. The added benefit of zk-SNARKs is that the verifier can prove computation correctly without seeing what the inputs are. The verifier has zero knowledge of the inputs. At a high level zk-SNARKs requires computation procedures to be specified as arithmetic circuits. Iden3 has developed libraries that abstract complexities, such as circom, the circuit compiler, and snarksjs a Node.js, library for generating proofs given the compiled circuits.
A downside of zk-SNARKs is that it requires a one-time setup to be performed by a trusted party who created the application. Malicious parties can generated fake proofs. To reduce some trust in this process, multiparty computation is a way to distribute the setup step process among multiple participants who have no knowledge of each other. Trusted set up is known as “toxic waste” because a master key must be created and then destroyed but there’s always the risk that it wasn’t properly eradicated.
Bulletproofs is another zero-knowledge scheme which doesn’t require a trust setup like in zk-SNARKs. Initially bulletproofs were designed for efficient range proofs for confidential transactions. In general zk-SNARKs is more appropriate for complex statements while bulletproofs more appropriate for simpler statements. A downside of bulletproofs is that verification is more time consuming than a snark proof.
Zk-STARKs like bulletproofs don’t require a setup phase since it doesn’t rely on public private key cryptography, however proof size are still relatively large to be used in practice.
Zcash uses zk-SNARKs but will eventually migrate to zk-STARKs. StarkWare and the Zcash Company are active researchers in zk-STARKS to enable privacy features in blockchain. Monero is using bulletproofs for range proofs.
Conclusion
We took a look at ways to move storage and computation to off-chain models, as well as how privacy of data and inputs can be preserved with the off-chain approaches. Off-chain storage is no longer restricted to on-chain requirements and computations can be more complex and agnostic to software stacks being used.
Sources:
- https://www.ise.tu-berlin.de/fileadmin/fg308/publications/2018/Off-chaining_Models_and_Approaches_to_Off-chain_Computations.pdf
- http://www.ise.tu-berlin.de/fileadmin/fg308/publications/2017/2017-eberhardt-tai-offchaining-patterns.pdf
- https://crypto.stanford.edu/bulletproofs/
- https://www.multichain.com/blog/2018/06/scaling-blockchains-off-chain-data/
- https://ethresear.ch/t/minimal-viable-plasma/426
- https://ethresear.ch/t/a-minimal-state-execution-proposal/4445